· Synx Data Labs
Modern Enterprise Data Warehouse Trends in 2026
Discover the key trends shaping the future of enterprise data warehousing in 2026, from AI-integrated engines to the rise of the Open Lakehouse.
As data continues to solidify its position as the core asset of the modern enterprise, the platforms used to store, manage, and analyze this data are undergoing a radical transformation. In the early days of enterprise analytics, IT departments focused primarily on descriptive analysis, utilizing traditional relational databases and reports to understand historical business performance, answering the basic question of “What happened?” Today, organizations demand predictive and prescriptive insights, requiring answers to “what is about to happen?” and “how do we drive business autonomously?”
To meet these demands, data architects are entirely rethinking their infrastructure. The current landscape of enterprise data warehouse platforms is characterized by democratization, automation, and integrated intelligence. This forward-looking guide explores the modern enterprise data warehouse trends reshaping the industry, examining the technological shifts from cloud-native architectures and lakehouse paradigms to real-time processing and AI-ready data foundations.
The Shift Toward Cloud Data Warehouse Platforms
One of the most foundational modern enterprise data warehouse trends is the wholesale migration to cloud data warehouse platforms. Traditional architectures often relied on tightly coupled compute and storage, which created resource contention, poor scalability, and expensive hardware overprovisioning. Modern cloud platforms solve this through full compute-storage separation.
In platforms like Snowflake, for instance, data resides in a centralized cloud storage layer accessible to all compute nodes, similar to a shared-disk architecture, while the compute layer utilizes independent virtual warehouses that process queries in parallel, mimicking a shared-nothing setup.
This architectural decoupling provides several critical advantages for enterprise data architects:
- Dynamic Scalability: Organizations can handle massive, unpredictable data spikes without the need for costly hardware over-provisioning.
- Resource Isolation: By completely separating compute resources, platforms eliminate the “noisy neighbor” issue in multi-tenant environments, ensuring that heavy data engineering workloads do not impact the performance of concurrent BI queries.
- Cost Efficiency: The transition from rigid CAPEX investments to flexible OPEX models allows for granular, per-second billing, significantly lowering the Total Cost of Ownership (TCO).
The Convergence into Lakehouse Architecture
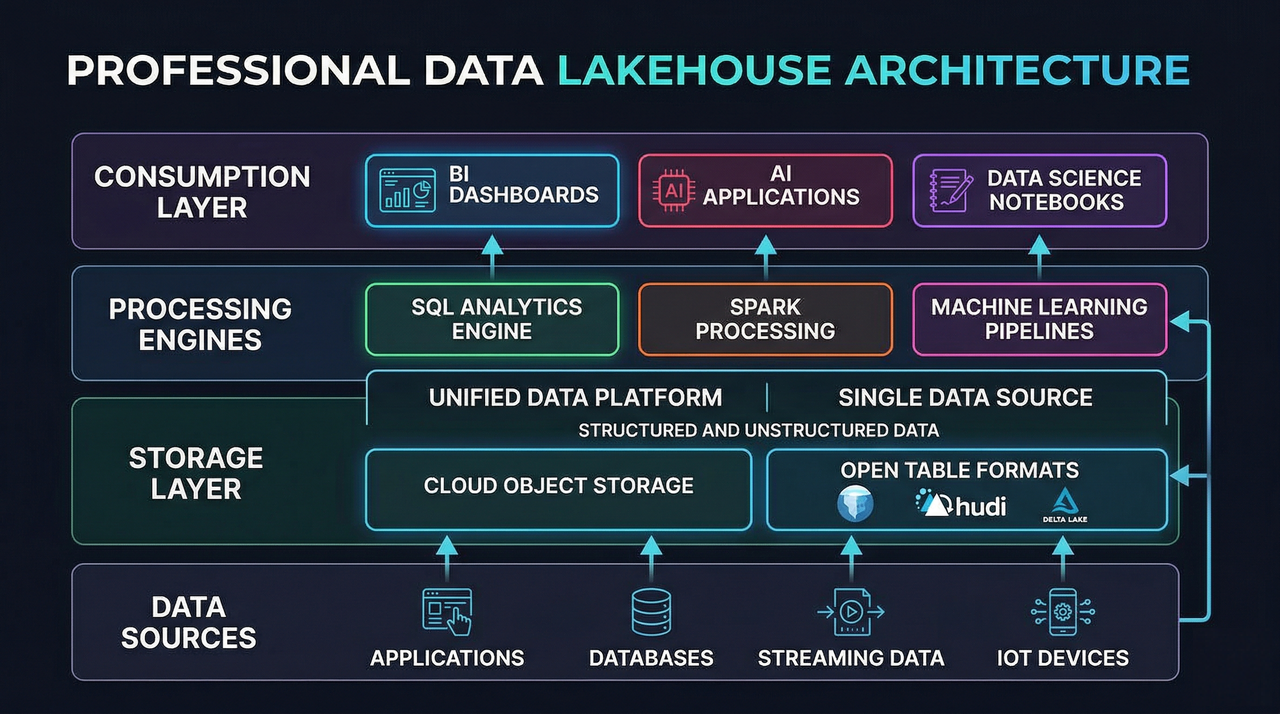
Historically, enterprises maintained separate systems: warehouses for governed SQL analytics and data lakes for large-scale raw storage and experimentation. This dual-stack model increased ETL complexity, created redundant datasets, and introduced governance gaps.
Modern lakehouse platforms unify these capabilities by combining warehouse-grade reliability with the flexibility and cost efficiency of cloud object storage.
Open table formats such as Apache Iceberg, Apache Hudi, and Delta Lake now enable:
- ACID transactions on object storage
- Schema evolution
- Time travel
- Data quality enforcement
- High-performance SQL access
This allows enterprises to consolidate BI, data engineering, and machine learning workflows on a single architectural foundation.
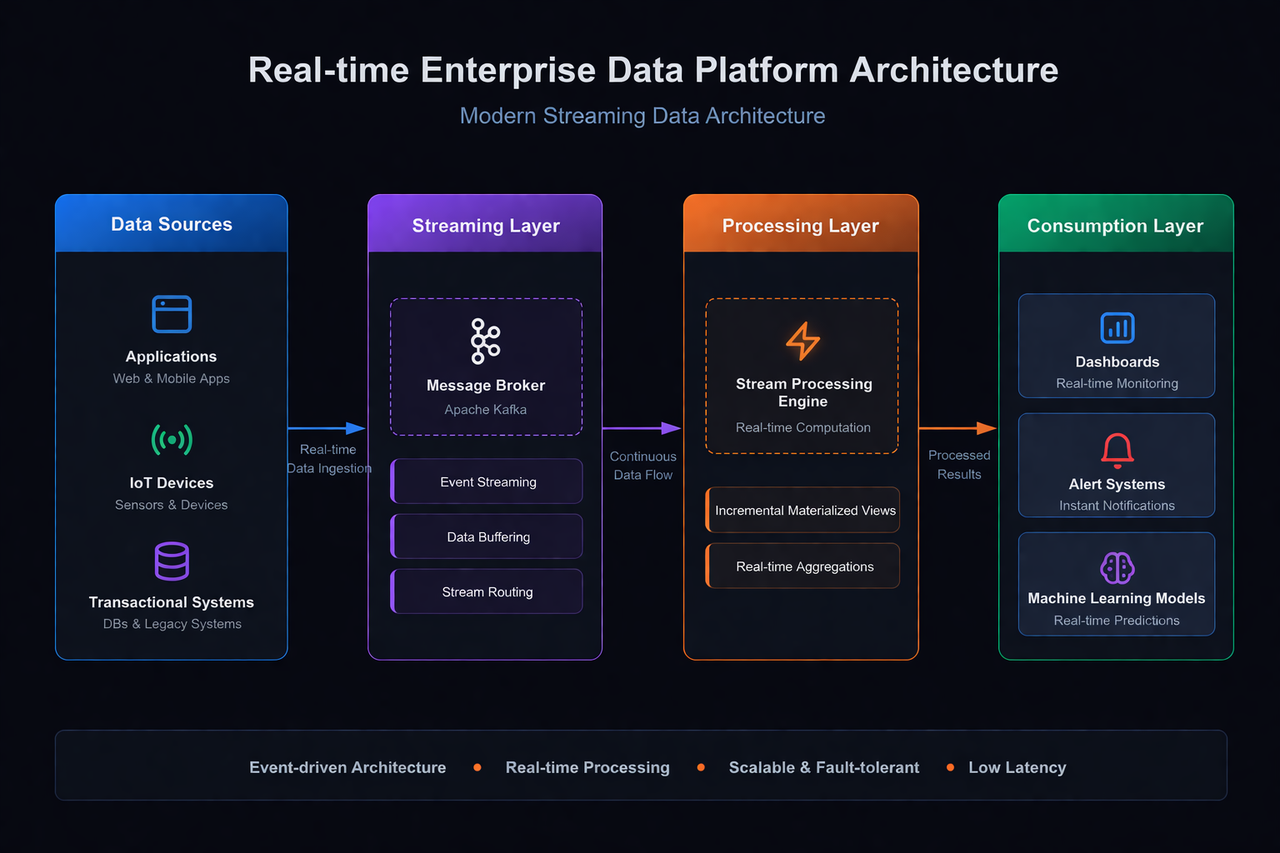
The Imperative for Real-Time Analytics
Batch processing and T+1 data latency are no longer sufficient for modern digital businesses that require immediate responses to operational anomalies or customer behaviors. As a result, there is a strong industry trend toward real-time analytics.
Modern warehouse platforms now integrate natively with streaming systems such as Apache Kafka, enabling continuous ingestion of event streams alongside batch data.
To support real-time dashboards without sacrificing performance, many platforms rely on:
- Incremental materialized views
- Dynamic aggregations
- Streaming ETL pipelines
- Continuously refreshed semantic layers
These capabilities allow teams to power live operational dashboards and automated alerting systems directly from the warehouse layer.
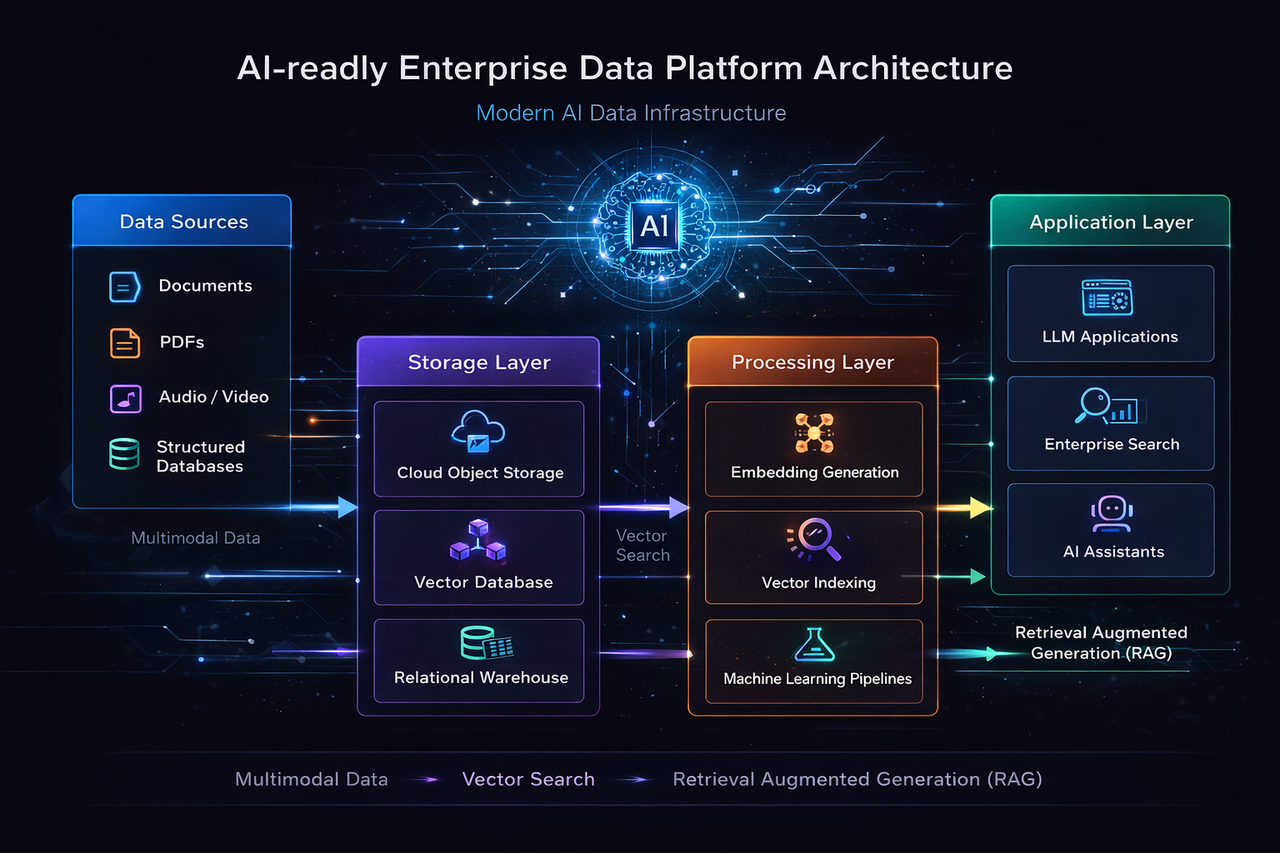
Building AI-Ready Data Platforms for Multimodal Data
The generative AI revolution has dramatically altered the requirements for enterprise data platforms. It is no longer enough to process purely structured rows and columns. To power modern AI applications, data architecture must extend beyond the traditional lakehouse to become a truly unified platform capable of multimodal data management. Enterprises are now storing and analyzing semi-structured data (JSON, XML), unstructured data (text documents, PDFs, audio, video), and real-time streams within the same logical ecosystem.
Furthermore, AI-ready data platforms are embedding advanced machine learning libraries and vector search capabilities directly into the database engine. For instance, integration with extensions like pgvector enables the high-performance storage and retrieval of vector embeddings. This is foundational for building Retrieval-Augmented Generation (RAG) architectures securely within the enterprise firewall. By performing embedding generation, contextual indexing, and vector similarity searches in-database, organizations can ground Large Language Models (LLMs) in proprietary enterprise data without exposing sensitive information to external APIs.
Practical Enterprise Data Architecture Scenario
Many modern enterprise data warehouse platforms now support federated querying and logical data warehousing through connectors, open table formats, and external table frameworks. This allows organizations to query data across legacy systems, object storage, and cloud databases without excessive ETL movement.
A strong real-world example is the rise of secure private AI knowledge assistants.
Consider a large telecommunications or financial institution building an internal AI chatbot to help customer service teams search millions of historical policy PDFs, call logs, and operational documents.
Using an AI-ready warehouse platform, architects can store raw files in cloud object storage, automatically parse and chunk the content, generate vector embeddings, and persist them in specialized vector tables.
When an agent submits a question, the system performs high-concurrency vector similarity search to retrieve the most relevant document segments before passing the context to an internal LLM.
The result is a secure, low-hallucination enterprise knowledge assistant fully governed by existing RBAC, auditing, and compliance controls.
Comparing Major Enterprise Data Warehouse Platforms
As enterprises modernize their analytics stack, platform selection increasingly comes down to workload profile, ecosystem alignment, deployment flexibility, and long-term AI strategy. While the market has consolidated around several dominant architectural philosophies, each platform still reflects a distinct design center.
| Platform | Best For | Core Strength | AI / ML Readiness | Deployment Flexibility | Pricing Model |
|---|---|---|---|---|---|
| Snowflake | SQL-heavy BI, dashboards, governed data sharing | SaaS simplicity, compute-storage separation, zero-copy sharing | Snowpark, Cortex AI, Python/Java support | Multi-cloud SaaS | Consumption-based |
| Databricks | Lakehouse, ML pipelines, advanced ETL | Delta Lake, notebook workflows, end-to-end ML lifecycle | Strong MLflow and vector-native workflows | Cloud-native, cloud-dependent | DBU consumption |
| Google BigQuery | Serverless analytics at petabyte scale | Zero-ops infrastructure, strong streaming and SQL performance | BigQuery ML, Vertex AI integration | Primarily GCP | Query-based or reserved capacity |
| Amazon Redshift | AWS-centric enterprise analytics | Deep AWS integration, Spectrum lake querying | SageMaker integration, external ML workflows | AWS-first | Node or serverless pricing |
| SynxDB | Hybrid lakehouse, open MPP analytics, multimodal enterprise workloads | Open MPP core, Iceberg/Hudi support, strong federation | Native vector search, Python/R, MADlib, multimodal AI | On-prem, multi-cloud, hybrid | Flexible subscription or consumption |
Strategic Summary
The right enterprise data warehouse platform depends less on brand preference and more on workload concurrency, governance boundaries, ecosystem dependencies, and AI roadmap maturity.
- Organizations prioritizing plug-and-play SQL analytics often favor Snowflake
- Teams building lakehouse-first ML workflows typically choose Databricks
- Enterprises seeking serverless elasticity inside GCP often prefer BigQuery
- AWS-centric architectures naturally align with Redshift
- For organizations requiring open MPP scalability, hybrid deployment, data federation, and in-database vector AI, SynxDB provides a strong low-lock-in foundation
As modern data platforms increasingly converge around lakehouse and AI-ready architectures, the most future-proof choice is the one that best aligns with both current analytics needs and long-term multimodal AI initiatives.
Conclusion
Enterprise data warehouse trends in 2026 clearly point toward platforms that are cloud-native, lakehouse-oriented, real-time, and AI-ready.
The shift from monolithic on-premises databases to elastic cloud architectures has transformed how enterprises manage scalability, governance, and cost efficiency. At the same time, the integration of open table formats, streaming pipelines, and vector-native AI capabilities is dissolving the boundaries between data warehousing, data lakes, and machine learning systems.
Whether an organization chooses a fully managed SaaS warehouse, a Spark-driven lakehouse, or an open MPP analytics platform, the long-term goal remains the same: turning multimodal enterprise data into secure, real-time, automated business intelligence.